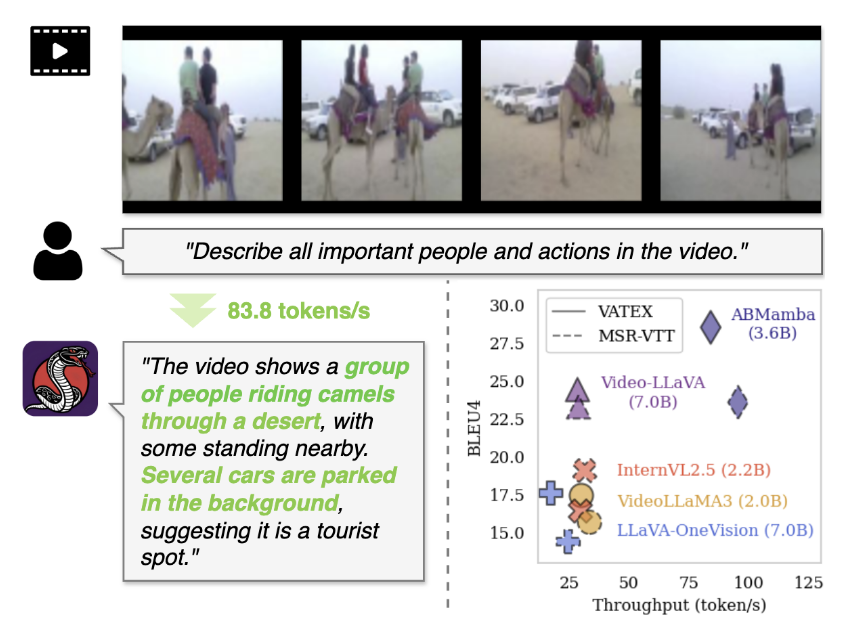
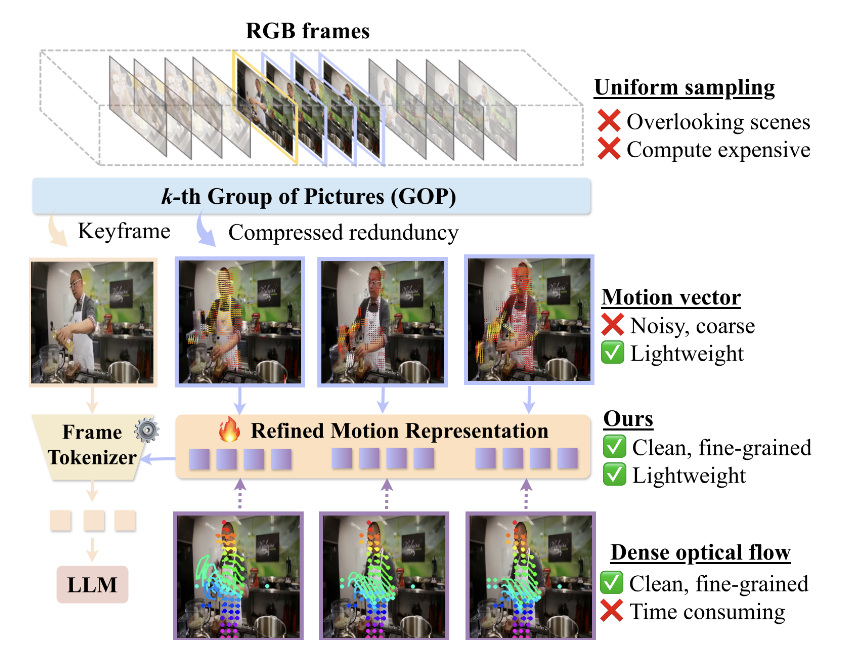
ABMAMBA: Multimodal Large Language Model with Aligned Hierarchical Bidirectional Scan for Efficient Video Captioning
ICPR 2026 • 2026 (h5-index: 68)

ICPR 2026 • 2026 (h5-index: 68)
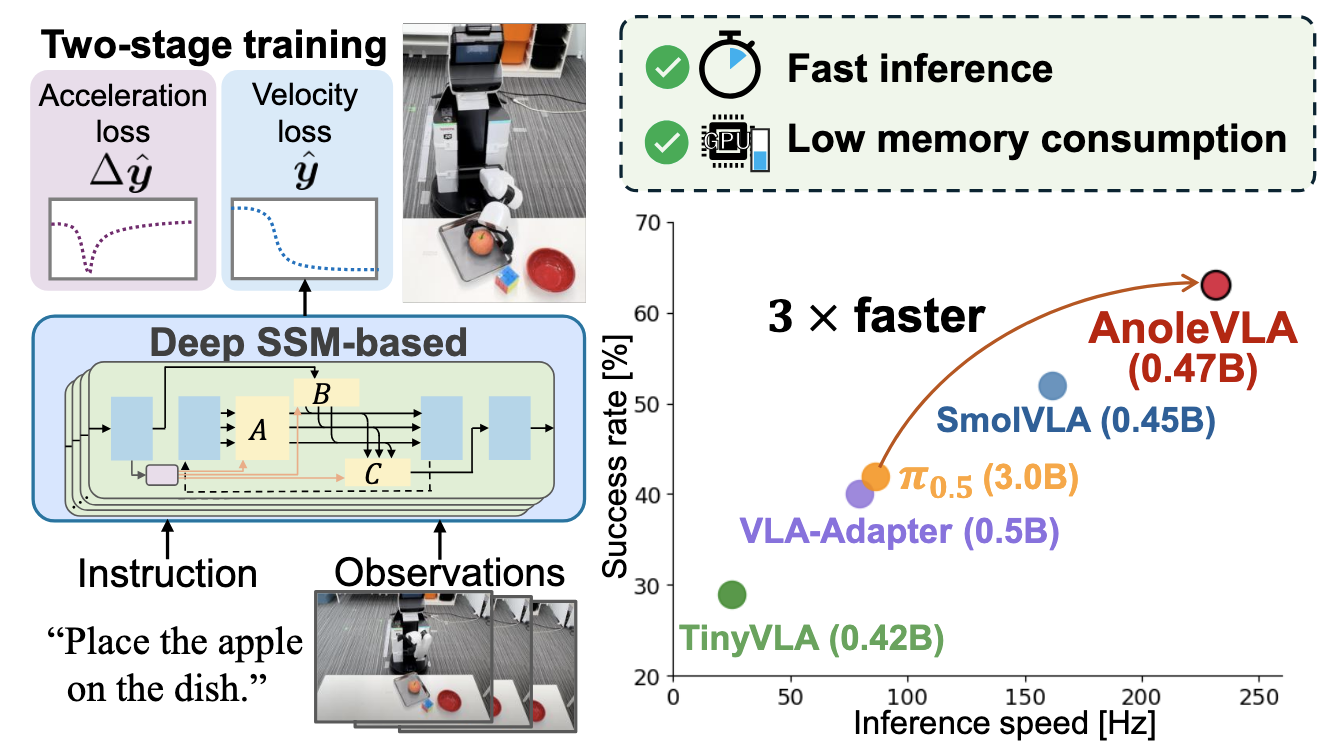
CVPR 2026 • 2026 (Acceptance Rate: 25.42%, h5-index: 450)

CVPR 2026 Findings • 2026 (Acceptance Rate (main + findings): 36%, h5-index: 450)
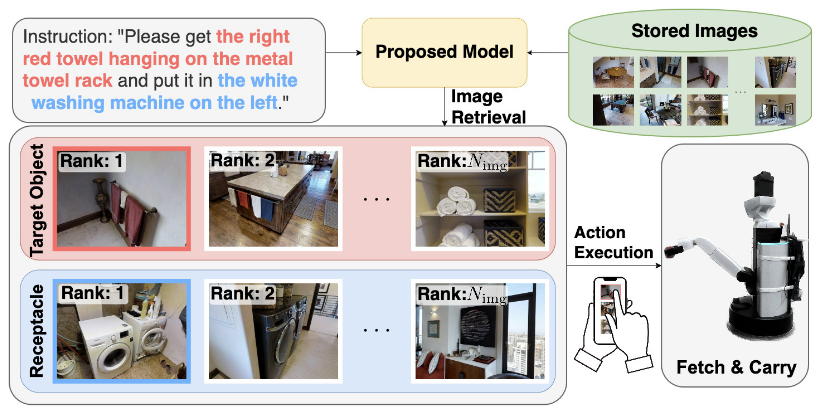
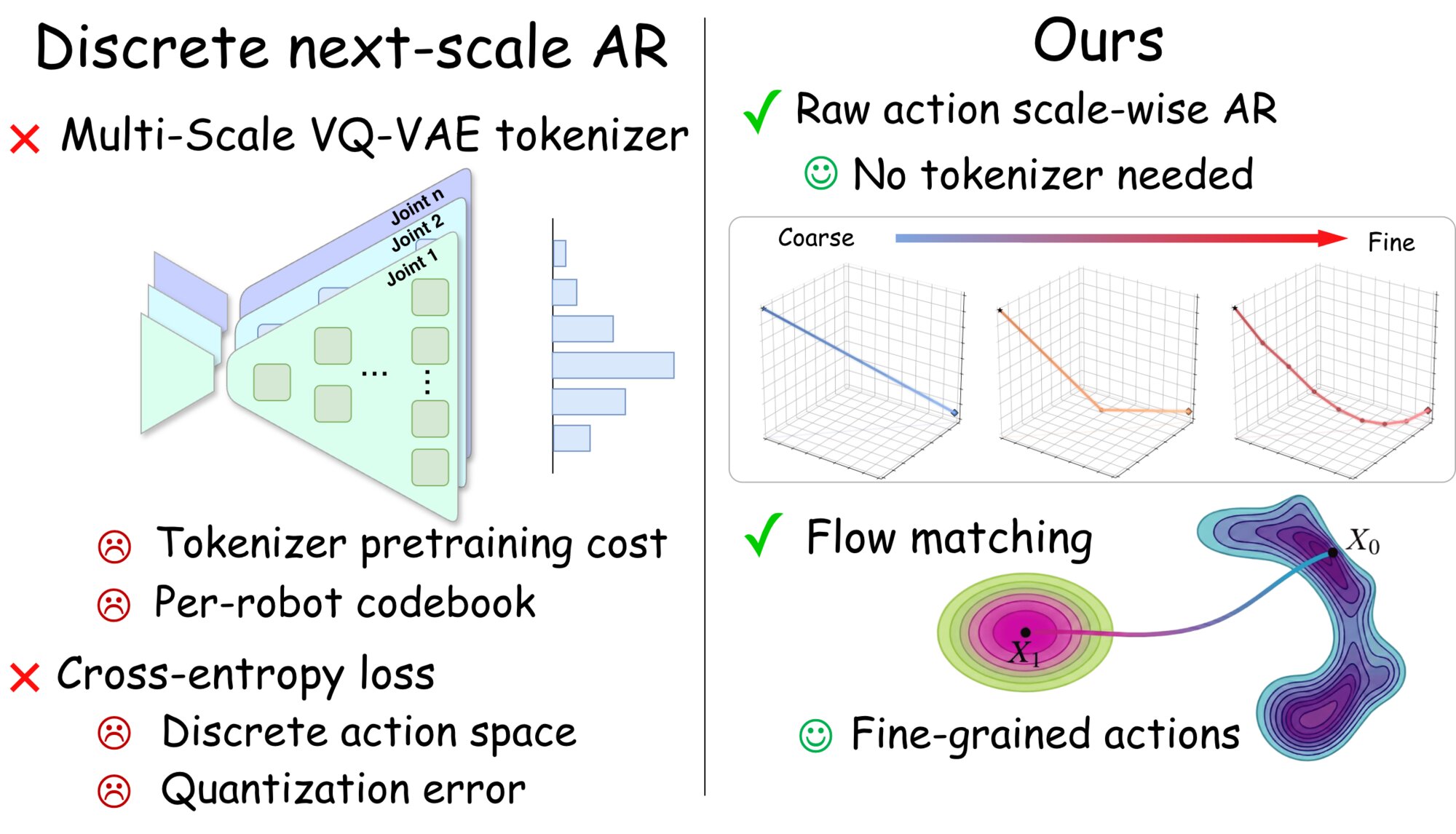
IEEE RA-L • 2025 (IF: 5.2, h5-index: 132)
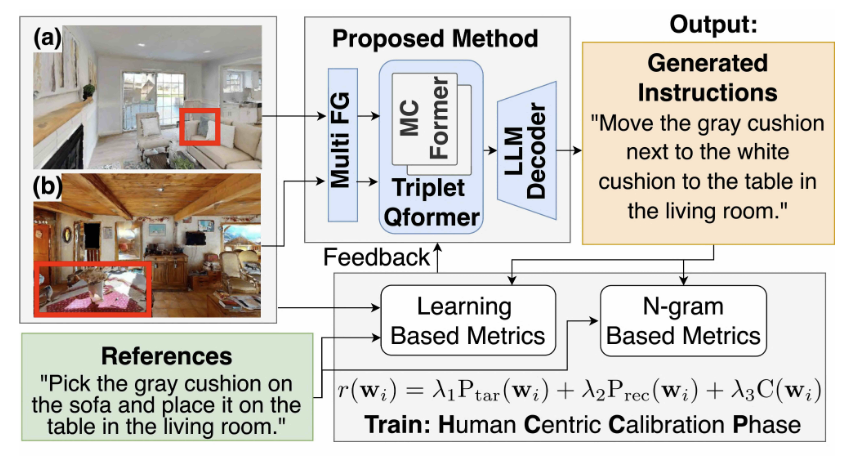
IEEE RA-L • 2025 (IF: 5.2, h5-index: 132)