
ABMAMBA: Multimodal Large Language Model with Aligned Hierarchical Bidirectional Scan for Efficient Video Captioning
Published in ICPR 2026, 2026
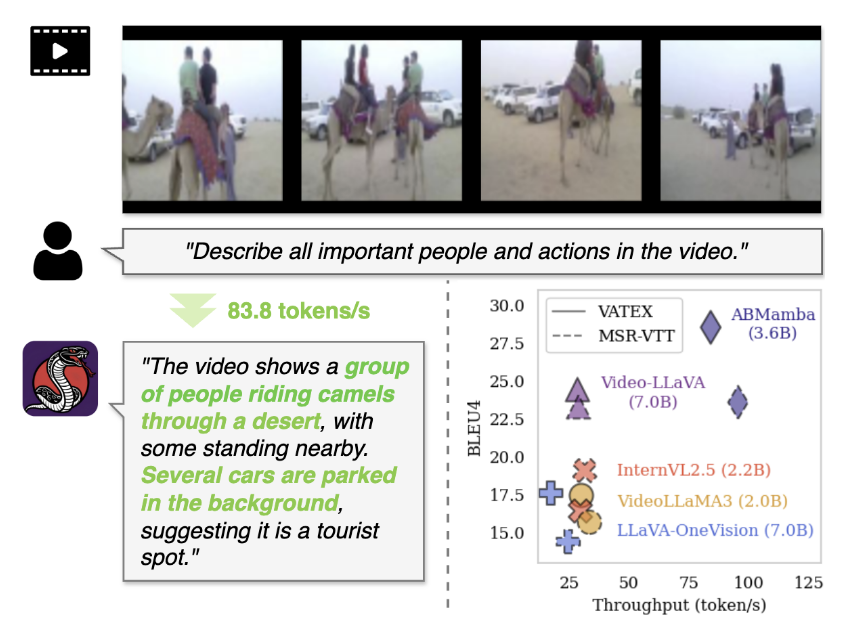
We propose ABMamba, a fully open MLLM based on Deep State Space Models with linear computational complexity that enables scalable video captioning. ABMamba replaces quadratic attention mechanisms with Deep SSMs and employs a novel Aligned Hierarchical Bidirectional Scan module that processes videos across multiple temporal resolutions. On standard video captioning benchmarks such as VATEX and MSR-VTT, ABMamba demonstrates competitive performance compared to typical MLLMs while achieving approximately three times higher throughput.
Citation: D. Yashima, S. Kurita, Y. Oda, S. Suzuki, S. Otsuki, and K. Sugiura, "ABMAMBA: Multimodal Large Language Model with Aligned Hierarchical Bidirectional Scan for Efficient Video Captioning", ICPR, 2026.
Download Paper