
ReMoRa: Multimodal Large Language Model based on Refined Motion Representation for Long-Video Understanding
Published in CVPR 2026, 2026
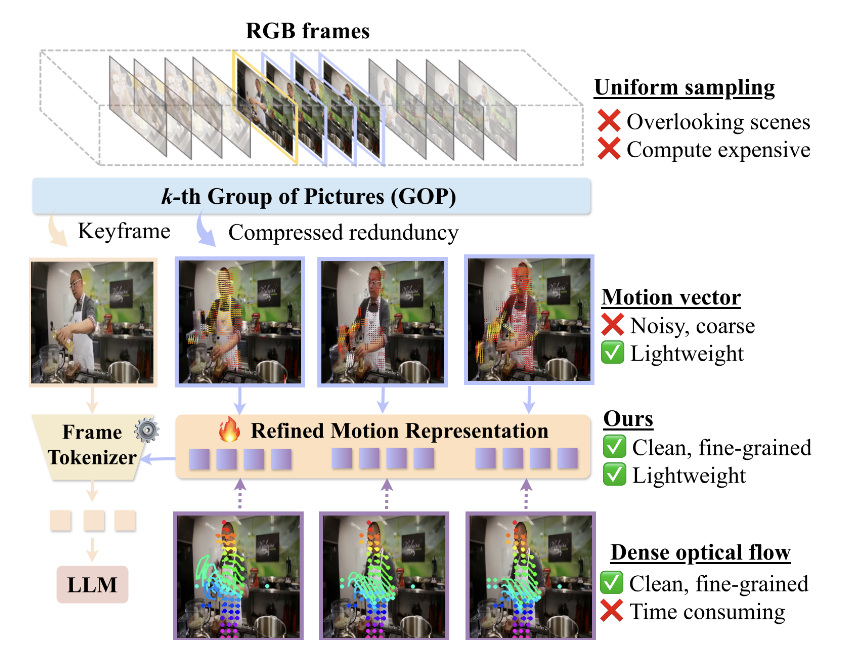
While multimodal large language models (MLLMs) have shown remarkable success across a wide range of tasks, long-form video understanding remains a significant challenge. In this study, we focus on video understanding by MLLMs. This task is challenging because processing a full stream of RGB frames is computationally intractable and highly redundant, as self-attention have quadratic complexity with sequence length. In this paper, we propose ReMoRa, a video MLLM that processes videos by operating directly on their compressed representations. A sparse set of RGB keyframes is retained for appearance, while temporal dynamics are encoded as a motion representation, removing the need for sequential RGB frames. These motion representations act as a compact proxy for optical flow, capturing temporal dynamics without full frame decoding. To refine the noise and low fidelity of block-based motions, we introduce a module to denoise and generate a fine-grained motion representation. Furthermore, our model compresses these features in a way that scales linearly with sequence length. We demonstrate the effectiveness of ReMoRa through extensive experiments across a comprehensive suite of long-video understanding benchmarks. ReMoRa outperformed baseline methods on multiple challenging benchmarks, including LongVideoBench, NExT-QA, and MLVU.
Citation: D. Yashima, S. Kurita, Y. Oda, and K. Sugiura, "ReMoRa: Multimodal Large Language Model based on Refined Motion Representation for Long-Video Understanding", CVPR, 2026.
Download Paper