
MLLM-as-a-Judge Exhibits Model Preference Bias
Published in arXiv, 2026
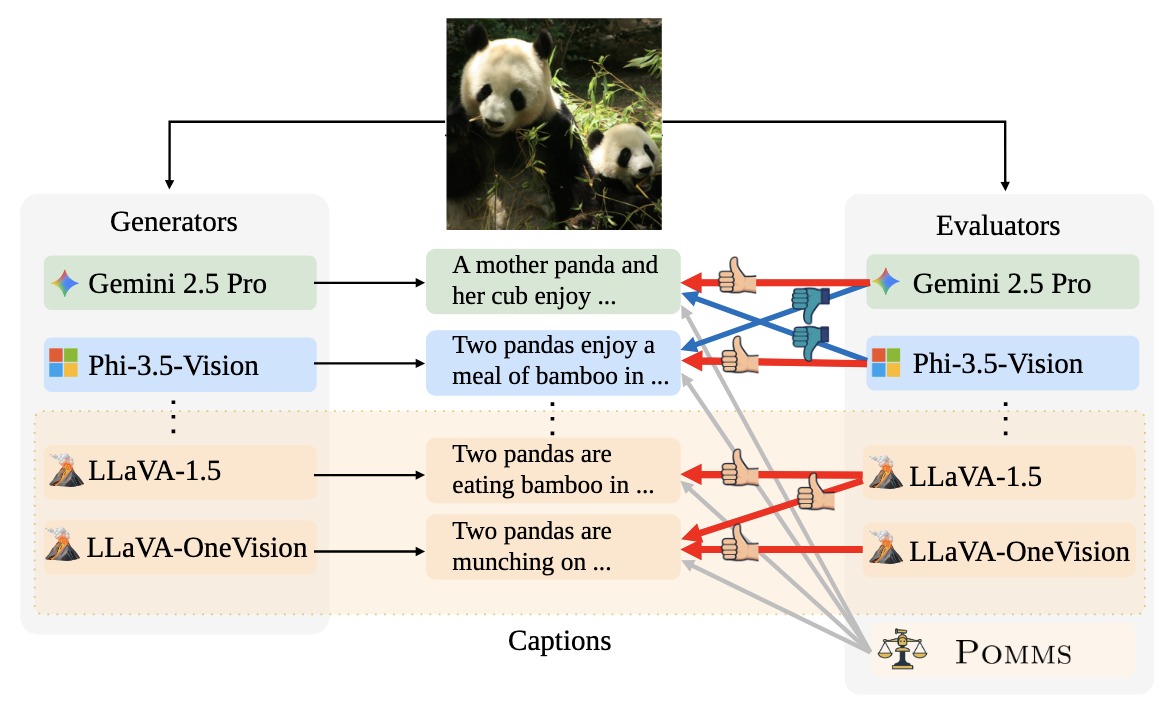
We investigate whether multimodal large language models used for automatic evaluation demonstrate bias toward outputs from specific models. Using data from 12 MLLMs, we find that these systems tend to exhibit self-preference bias, and that models from the same family show mutual preference biases, potentially due to shared technical components. We propose an ensemble method called Pomms that successfully reduces this bias while maintaining evaluation quality.
Citation: S. Koyama, Y. Wada, D. Yashima, and K. Sugiura, "MLLM-as-a-Judge Exhibits Model Preference Bias", arXiv, 2026.
Download Paper